


下载文件
学习资料:
从网上下载文件的时候你肯定很开心, 比如说什么电影, pdf, 音乐等. 我们使用爬虫, python 一样也可以做到. 而且做得途径还有很多. 今天我们就来探讨有哪些可行的途径, 之后我们还能用这些途径来做一个小实战, 下载国家地理杂志上的美图.
下载之前¶
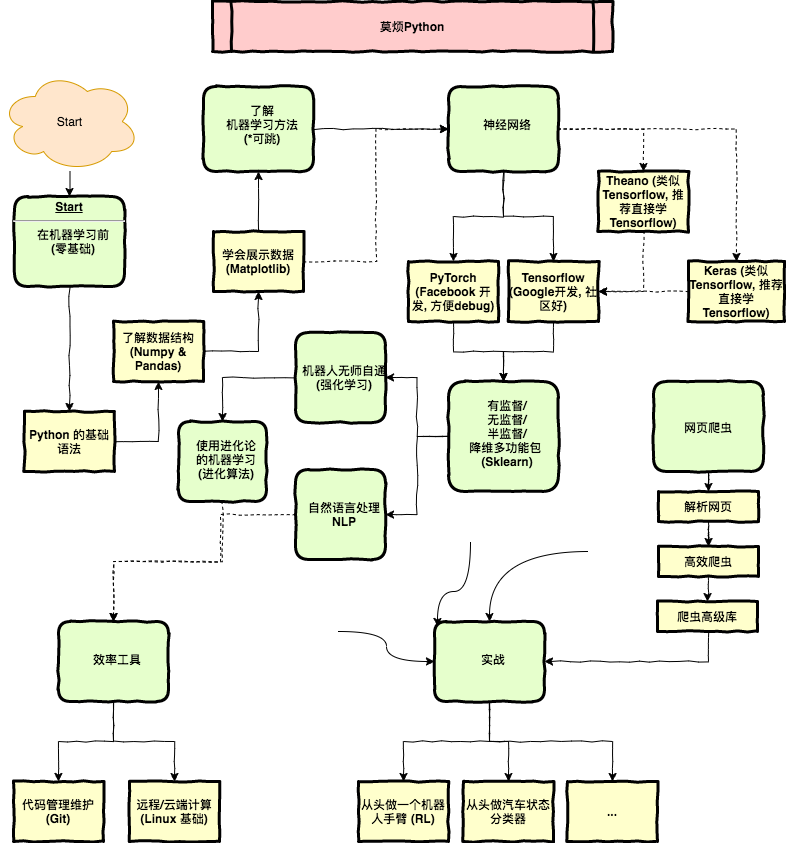
在下载之前, 我们的弄清楚怎么样下载. 打个比方, 以前有朋友留言说我的教程太多, 不知道从何学起, 我专门制作了一张学习流程图, 这张莫烦Python的个性化学习路线应该也拯救了无数迷途少年吧. 哈哈哈, 今天我们来爬这张图, 还有下载这张图.

想下这张图, 我们首先要到这张图所在的网页. 在这个网页中找到这张图的位置, 并右键 inspect, 找到它在 HTML 中的信息.

发现原图被存放在这个网页, 注意这个地址开头是 /, 并不是完整的网址, 这种形式代表着, 它是在 https://mofanpy.com/
下面的网址. 所以我们还要将其补全, 才能在网址栏中找到这个图片地址.
src="/static/img/description/learning_step_flowchart.png"
补全后的网址是:
{kind=link}
https://mofanpy.com/static/img/description/learning_step_flowchart.png
找到了这个网址, 我们就能开始下载了. 为了下载到一个特定的文件夹, 我们先建立一个文件夹吧. 并且规定这个图片下载地址.
使用 urlretrieve¶
在 urllib 模块中, 提供了我们一个下载功能 urlretrieve. 使用起来很简单. 输入下载地址 IMAGE_URL 和要存放的位置. 图片就会被自动下载过去了.
使用 request¶
而在 requests 模块, 也能拿来下东西. 下面的代码实现了和上面一样的功能, 但是稍微长了点. 但我们为什么要提到 requests 的下载呢? 因为使用它的另一种方法, 我们可以更加有效率的下载大文件.
所以说, 如果你要下载的是大文件, 比如视频等. requests 能让你下一点, 保存一点, 而不是要全部下载完才能保存去另外的地方. 这就是一个 chunk 一个 chunk 的下载. 使用 r.iter_content(chunk_size) 来控制每个 chunk 的大小, 然后在文件中写入这个 chunk 大小的数据.
有了这些知识的积累, 我们就能开始做一个小的实战练习, 去下载一些国家地理杂志的美图啦.
相关教程
降低知识传递的门槛
莫烦经常从互联网上学习知识,开源分享的人是我学习的榜样。 他们的行为也改变了我对教育的态度: 降低知识传递的门槛。
我组建了微信群,欢迎大家加入,交流经验,提出问题,互相帮持。 扫码后,请一定备注"莫烦",否则我不会同意你的入群申请。
