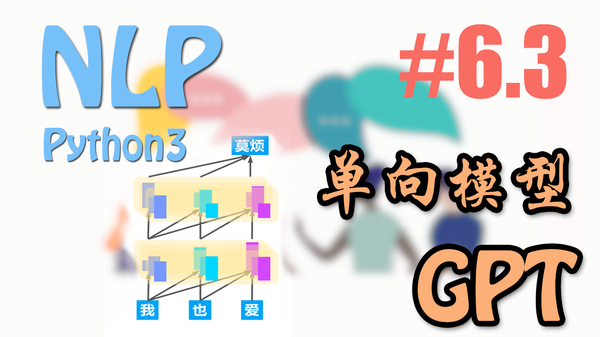


GPT 单向语言模型
学习资料:
- 本节的全部代码
- 代码依赖的 utils.py 和 visual.py 在这里找到
- 我制作的 预训练语言模型 短片简介
- GPT 论文:Improving Language Understanding by Generative Pre-Training
- GPT2 论文:Language Models are Unsupervised Multitask Learners
- GPT3 论文:Language Models are Few-Shot Learners
怎么了¶
我们已经知道模型越来越大的好处很显而易见,模型能用更多非线性能力处理更复制的问题。但是由此带来另一个难题,就是难以训练。每训练一个超大模型, 我们都要消耗更多计算资源和更多时间。有人就做过一个研究,用他们提到的一种方式,训练一个自然语言的Transformer模型, 居然要排放180吨的二氧化碳。这足足可以让一个人坐飞机往返旧金山和纽约200次了。 可见模型大了还可能会带来环境问题。
有没有什么好办法同时享受准确率的同时又不费时间不费力的训练模型呢?预训练就是你要找的这颗药丸。 你也可以观看我制作的这个短片简介来快速了解预训练模型的好处。
今天我们要学习的是一个在自然语言中比ELMo更厉害的模型。 这个模型玩的不是RNN那一套循环机制,而是Transformer的注意力机制。 它成功地将Transformer的注意力运用在语言模型中,并且让模型能够非常精准的预测出答案,在很多方面让人类打开眼界。
这个模型就是 Generative Pre-Training (GPT) 模型。目前这个模型已经迭代了3个版本了,最强的一个GPT3,媒体已经将其夸上了天。不过抛开噱头部分, GPT3的确算是在NLP里面的优秀模型。

直接从文字自动生成网页html,css代码,转换成网页。(前端工程师是不是要失业了??)

直接从文字自动生成论文中的公式,天哪,学术界的福星,再也不用编辑复杂的论文公式了!!

完了,连算法研究员都要失业了。你直接对着屏幕说要怎样的模型,模型的代码就写好了。(完了完了,我们自己都没救了)
这都还只是GPT3的冰山一角,只要发挥我们的想象力,还能做出更多有趣的应用(让更多人失业~)。
GPT是啥¶
GPT主要的目标还是当好一个预训练模型该有的样子。用非监督的人类语言数据,训练一个预训练模型,然后拿着这个模型进行finetune, 基本上就可以让你在其他任务上也表现出色。因为下游要finetune的任务千奇百怪,在这个教学中,我会更专注GPT模型本身。 告诉你GPT模型到底长什么样,又会有什么样的特性。至于后续的finetune部分,其实比起模型本身,要容易不少。
具体到GPT的模型,其实它和Transformer有着目不可分的联系。还不了解Transformer的同学, 强烈建议你先看看我的这个短片简介和Transformer的代码实现。 有人说它是Transformer的Decoder,但是我觉得这可能并不准确。 它更像是一种Transformer Decoder与Encoder的结合。用着Decoder的 Future Mask (Look Ahead Mask),但结构上又更像Encoder。
说说为什么这样设计吧。说到底,这么设计就是为了让GPT方便训练。用前文的信息预测后文的信息,所以用上了Future Mask。

如果不用Future Mask, 又要做大量语料的非监督学习,很可能会让模型在预测A时看到A的信息,从而有一种信息穿越的问题。 具体解释一下,因为Transformer这种MultiHead Attention模式,每一个Head都会看到所有的文字内容,如果用前文的信息预测后文内容,又不用Future Mask时, 模型是可以看到要预测的信息的,这种训练是无效的。 Future Mask的应用,就是不让模型看到被穿越的信息,用一双无形的手,蒙蔽了它的透视眼。
另外一个与Transformer Decoder的不同之处是,它没有借用到Encoder提供的 self-attention 信息。所以GPT的Decoder要比Transformer少一些层。 那么最终的模型乍一看的确和Transformer的某一部分很像,不过就是有两点不同。
- Decoder 少了一些连接 Encoder 的层;
- 只使用Future Mask (Look ahead mask)做注意力。

学习案例¶
和训练ELMo一样,我们拥有网络上大量的无标签数据,语言模型进行无监督学习,训练出一个pretrained模型就有了优势。 这次的案例我们还是使用在ELMo训练的 Microsoft Research Paraphrase Corpus (MRPC) 数据。 可以做一个横向对比。这个数据集的内容大概是用这种形式组织的。
| Quality | #1 ID | #2 ID | #1 String | #2 String |
|---|---|---|---|---|
| 1 | 1089874 | 1089925 | PCCW 's chief operating officer , Mike Butcher , and Alex Arena , the chief financial officer , will report directly to Mr So . | Current Chief Operating Officer Mike Butcher and Group Chief Financial Officer Alex Arena will report to So . |
| 0 | 1430402 | 1430329 | A tropical storm rapidly developed in the Gulf of Mexico Sunday and was expected to hit somewhere along the Texas or Louisiana coasts by Monday night . | A tropical storm rapidly developed in the Gulf of Mexico on Sunday and could have hurricane-force winds when it hits land somewhere along the Louisiana coast Monday night . |
每行有两句话 #1 String 和 #2 String, 如果他们是语义相同的话,Quality 为1,反之为0。这份数据集可以做两件事:
- 两句合起来训练文本匹配;
- 两句拆开单独对待,理解人类语言,学一个语言模型。
这个教学中,我们在训练语言模型的时候,用的是无监督的方法训练第2种模式。但同时也涉及到了第1种任务。 为什么在ELMo教学中没有涉及第一种?因为我懒,哈哈哈。 如果为懒要找一个借口,那我就说:我们在ELMo中体验过了直接做无监督学习,但是除了无监督能训练,我们同样还能引入有监督的学习, 这次GPT就带你体验一把同时训练无监督和有监督的做法。
其实我们可以将无监督看成是一个task,预测是否是下一句看成另一个task,当然task还能有很多。就看你的数据支持的是什么样的task了。 多种task一起来训练一个模型,能让这个模型在更多task上的泛化能力更强。
先给你看看最终的训练结果会是怎样吧~

秀代码¶
我在下面的内容中会尽量精简代码的内容,突出代码的框架性结构,为你清晰地突出重点部分。 如果你习惯直接看全部代码,请点击这里。
首先还是我们的训练步骤,因为训练的循环是最能看出来训练时的差异化的。
同之前的教学模式,这里的utils.MRPCData(), 我已经将他们封装好,帮你减轻了使用负担,因为你的主要目标是弄懂GPT是如何工作的,而不是数据怎样处理。 model.step()中,
seqs[:, :-1]是X input中的句子信息,segs[:, :-1]是X input的前后句信息,判断是否是前句还是后句。因为我们会同时将前句和后句放在seqs中一起给模型,所以模型需要搞清楚他到底是前句还是后句。seqs[:, 1:]是非监督学习的Y信息,用前句预测后句。nsp_labels是判断输入的两句话是否是前后文关系。
总体来说,就是将前后句的文本信息和片段信息传入模型,让模型训练两个任务,1. 非监督的后文预测,2. 是否是下一句。
我们可以看到,如果展示出整个训练的结果,它是这样的:
step: 0 | time: 0.63 | loss: 9.663
| tgt: they also are reshaping the retail business relationship elsewhere , as companies take away ideas and practices that change how they do business in their own firms and with others . <SEP> they also are reshaping the retail-business relationship , as companies take away concepts and practices that change how they do business internally and with others .
| prd: kinsley van-vliet franco atheist bottom kent performance toured trapeze reporting alta miz crush <NUM>-month crush kennedy dominick clarence ``will thames mr scanning abuses losses sleeping since detection punching scrutiny fare-beating shiites sue gagne canfor built schafer chronicle assignment cat deadline action slipping enhances crush tearing cat mobile widen treaty retire towards an-najaf virtually alta widen files gillian jamaica
step: 100 | time: 14.39 | loss: 8.227
| tgt: <quote> we are declaring war on sexual harassment and sexual assault . <SEP> <quote> we have declared war on sexual assault and sexual harassment , <quote> rosa said .
| prd: the the the the the the the the the , the the <SEP> the the , , , , , , , , , <NUM> <SEP> <SEP> <NUM> the
...
step: 4800 | time: 14.08 | loss: 0.612
| tgt: the rest said they belonged to another party or had no affiliation . <SEP> the rest said they had no affiliation or belonged to another party .
| prd: the company said they remain to another party or had no affiliation . <SEP> the rest said they had no affiliation or belonged to another party or
step: 4900 | time: 14.05 | loss: 0.677
| tgt: <quote> craxi begged me to intervene because he believed the operation damaged the state , <quote> mr berlusconi said . <SEP> <quote> i had no direct interest and craxi begged me to intervene because he believed that the deal was damaging to the state , <quote> berlusconi testified .
| prd: the the begged me to intervene because he believed the operation damaged the state , <quote> mr berlusconi said . <SEP> <quote> i had no direct interest and craxi begged me to intervene because in believed that the deal was damaging to the state , <quote> berlusconi testified .
经历了5000步的训练,从最开始频繁预测 the 变成最能够比较好预测句子的后半段内容。因为future mask的原因,GPT是没办法很好的预测句子的前半段的, 因为前半段的信息太少了。所以我们才说GPT是单向语言模型。
而模型的架构我们会使用到在Transformer中的Encoder代码,因为他们是通用的。 只是我们需要将Encoder中的Mask规则给替换掉。而且在模型中为seg和word多加上几个embedding参数。
定义好词向量word_emb,片段向量segment_emb,位置向量position_emb, 这三个向量表达,我们的输入端就完成了, 接着就是直接套用Transformer的encoder。如果你还不知道Transformer的encoder怎么搭建的,你一定一定要看看我更加详细的教学介绍。
用call()做前向预测的时候,X数据过一遍所有的embedding,然后直接进入Transformer的Encoder,拿到最后的注意后的结果。 最后经过两个输出端 mlm (非监督语言模型) 和 nsp (是否是前后句),完成两个任务的预测。 对于encoder中使用的mask,我们需要特别定义,因为之前上面也提到过,在GPT中的mask不是Transformer中的mask,因为GPT做非监督训练的时候, 是不能看到未来的信息的。所以,我们要定制一个future mask来蒙蔽它的双眼。
为什么不直接用Transformer中的lookaheadmask呢?其实也就是因为我写Transformer的时候,是将paddingmask和lookaheadmask分开写的。 但是GPT的future mask,我想把 paddingmask和lookaheadmask 合起来。所以重新写了一下。如果可视化出来,就是这样。
GPT的核心代码就这么多啦。哈哈哈,看起来很比Transformer少,那是因为你已经理解了Transformer,直接复用了Transformer的Encoder, 为你节约了很多时间和代码量。你看,只要循序渐进式的学习,学习就能变得很简单。
GPT注意力结果¶
模型经过5000步训练,已经能有效地注意到句子中的某些重要部分了。我们来看看矩阵形式的attention。 可视化的代码你可以在这里找到。 之后我们做BERT可视化的时候也会用到这份可视化代码。

矩阵的形式可能不太方便看出什么结果。所以我还是做了一个连线形式的。这种连线模式就能比较好看出每个词的注意力关系,线段粗的注意力就越大。 我输出的是最后一层网络的自注意力。在这一层中一共有4个head,所以相当于有4个人在看这些信息,每个人关注不同的部分。
我们还是可以观测到一些关键的注意节点的,head3在预测posted的时候,关注到的是前面的pearson。有趣的是,很多头都会用最开始的<GO>。 很有可能是这时候模型并不需要注意什么,为了不注意
,他们就将注意力分配到不重要的信息上,也就是这里的<GO>。
还能怎么玩¶
GPT 已经比ELMo好上很多了,但研究人员为了达到更高的效果,目前还有两个升级版。 GPT2(稍微调整了一下结构,主结构不变)增大了模型的体量, 它有1600维隐藏层,参数规模达15亿。 GPT3在GPT2的基础上再次拓展,变得更大,效果更好。1750亿个参数,真是大力出奇迹。如果你看数字没什么概念,给你上张图。
网上这张图,我们可以看看GPT3参数量的横向对比。

什么感受,天哪!GPT3的参数量已经不是其他模型能够相比的了。可见,在拼爹拼硬件的年代,拼NLP的效果,如果你爹不是Google,openAI,微软,阿里腾讯等,你是根本没有机会训练这样庞大的模型的。 唉,普通NLP玩家充当一下吃瓜群众就好了~
总结¶
如果说GPT是单向的Transformer语言模型,那么Bert就是双向的语言模型,BERT相比GPT,训练起来还是很有Trick的。 就是因为他的双向注意力,让它训练起来更加困难。我想如果BERT也可以达到1700+亿参数,效果应该也不会很差吧。
