

BERT 双向语言模型
学习资料:
- 本节的全部代码
- 代码依赖的 utils.py 和 visual.py 在这里找到
- 改进版BERT快速训练代码
- 我制作的 预训练语言模型 短片简介
- BERT 论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
怎么了¶
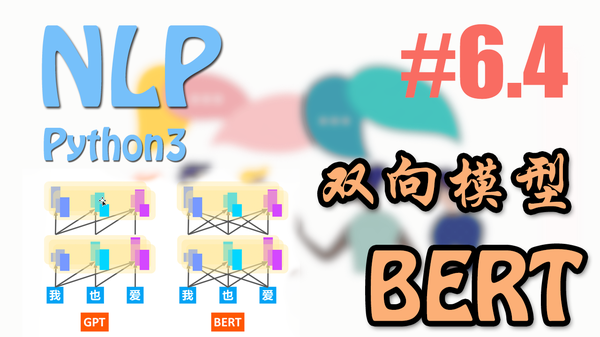
BERT 和 GPT 还有 ELMo 是一个性质的东西。 它存在的意义是要变成一种预训练模型,提供 NLP 中对句子的理解。ELMo 用了双向 LSTM 作为句子信息的提取器,同时还能表达词语在句子中的不同含义;GPT 呢, 它是一种单向的语言模型,同样也可以用 attention 的方式提取到更加丰富的语言意思信息。而BERT,它就和GPT是同一个家族,都是从Transformer 演变而来的。那么 BERT 和 GPT 有有什么不同之处呢?
其实最大的不同之处是,BERT 认为如果看一个句子只从单向观看,是不是还会缺少另一个方向的信息?所以 BERT 像 ELMo 一样,算是一种双向的语言模型。 而这种双向性,其实正是原封不动的 Transformer 的 Encoder 部分。

怎么训练¶
在看到后续内容之前,我强烈建议你先看一下我的 Transformer 教学,因为BERT就是一个Transformer的Encoder,只是在训练步骤上有些不同。 在这个教程中我就不会详细说明Encoder的结构了。
为了让BERT理解语义内容,它的训练会比GPT tricky得多。 GPT之所以训练方案上比较简单,是因为我们把它当成一个RNN一样训练,比如用前文预测后文(用mask挡住了后文的信息)。前后没有信息的穿越,这也是单向语言模型好训练的一个原因。 但是如果又要利用前后文的信息(不mask掉后文信息),又要好训练,这就比较头疼了。因为我在预测词X的时候,实际上是看着X来预测X,这样并没有什么意义。
好在BERT的研发人员想到了一个还可以的办法,就是我在句子里面遮住X,不让模型看到X,然后来用前后文的信息预测X。这就是BERT训练时最核心的概念了。

但是这样做又会导致一个问题。我们人类理解完形填空的意思,知道那个空
(mask)是无
或者没有
的意思。 但是模型不知道呀,它的空
(mask)会被当成一个词去理解。因为我们给的是一个叫mask
的词向量输入到模型里的。 模型还以为你要用mask
这个词向量来预测个啥。为了避免这种情况发生,研究人员有做了一个取巧的方案: 除了用mask
来表示要预测的词,我还有些时候,把mask
随机替换成其他词,或者原封不动。具体下来就是下面三种方式:
随机选取15%的词做如下改变
- 80% 的时间,将它替换成
[MASK] - 10% 的时间,将它替换成其他任意词
- 10% 的时间,不变
举个例子:
Input: The man went to [MASK] store with [MASK] dog
Target: the his
预测 [MASK] 是BERT的一项最主要的任务。在非监督学习中,我们还能怎么玩?让模型有更多的可以被训练的任务? 其实呀,我们还能借助上下文信息做件事,就是让模型判断,相邻这这两句话是不是上下文关系。

举个例子,我在一个两句话的段落中将这两句话拆开,然后将两句话同时输入模型,让模型输出True/False判断是否是上下文。 同时我还可以随机拼凑不是上下文的句子,让它学习这两句不是上下文。
Input : the man went to the store [SEP] he bought a gallon of milk [SEP]
Is next : True
Input = the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Is next : False
有了这两项任务,一个[MASK],一个上下文预测,我们应该就能创造出非常多的训练数据来给模型训练进行监督训练啦。 其实也就是把非监督的数据做成了两个监督学习的任务,模型还是被监督学习的。
请注意:我写的BERT代码和原文有一处不同,我认为不用传递给模型一个[CLS]信息让模型知道当前在做的是什么任务,因为我想要得到的是一个语言理解器, 至于对于不同的任务,可以 Finetune 出不同的头来适应,因为谁知道你下游是不是一个你训练过的任务(Task)呢?所以我觉得没必要专门为了Task去搞一个Task input。 我更关注的是训练出一个语言模型,而不是一个语言任务模型。
效果¶
我没有使用大数据,所以这个教学中的 BERT 训练出来的效果不会很好,但是多少还是有些注意力的有效分布。

秀代码¶
我们这里选择的数据还是和做ELMo,GPT 时相同的数据(MRPC),可以进行横向对比。 你可以点击下载训练数据, 测试数据。 或者我的 utils.py 里面调用 utils.MRPCData() 的时候会自动帮你下载。
如果你习惯直接看全部代码,请点击这里。
我们注意到 random_mask_or_replace() 在每次循环中,将数据进行了一次MASK和replace操作。目的就是为了让BERT有个可以被预测的词位。
通过上面的训练过程,如果我们打印出训练结果,可以发现,BERT在收敛,但是收敛的速度比GPT慢很多,我们上次训练的GPT只用了5000步就收敛到一个比较好的地方, 但是这次的BERT训练了10000步,还是没能收敛到特别好。这也是BERT在训练上的一个硬伤。
step: 0 | time: 0.64 | loss: 9.655
| tgt: <GO> <quote> we can 't change the past , sour we can schering-plough a lot about the future , <quote> sheehan said gamecocks a news conference wednesday afternoon . prevents <quote> we heads 't change the past leg but goldman can do a lot about analogous future , <quote> sheehan said hours after arriving in phoenix
| prd: tennis subject bar condition adviser down higher ko larned sleep charing arrest shipments alone corp. forging lord rucker humans requiring peaks assignment communion parking locked jeb novels aboard civilians sciences moroccan offer juvenile non-discriminatory reactors <NUM>-to-49-year-old slashed touch-screen underperformed aches trenton north partway odds tito websites company-sponsored orthopedic behind mother-of-two breaking campaigning cooperate down denver marched
| tgt word: ['but', 'do', 'at', '<SEP>', 'can', ',', 'we', 'the']
| prd word: ['sleep', 'shipments', 'communion', 'sciences', 'juvenile', 'touch-screen', 'aches', 'websites']
step: 100 | time: 14.04 | loss: 8.924
| tgt: <GO> this year , local health departments hired part-time water samplers and purchased testing equipment with a $ <NUM> grant from the environmental protection agency . <SEP> this year , peninsula health officials got the money to hire part-time water samplers and purchase testing equipment thanks to a $ <NUM> grant from the environmental protection agency
| prd: <GO> harrison operated <GO> <GO> , <GO> the the <SEP> <SEP> <GO> the the <SEP> manila stuck <SEP> the <GO> medics <SEP> <GO> <SEP> the sherry offend daschle cronan , washington-area , membership , the <NUM> , , the the the <NUM> the the the the , stricter <NUM> the , , the <NUM> the the
| tgt word: ['testing', 'with', '<NUM>', 'protection', ',', 'health', 'water', 'protection']
| prd word: ['the', 'manila', 'the', '<SEP>', ',', ',', 'the', 'the']
...
step: 9800 | time: 14.16 | loss: 2.888
| tgt: <GO> in <NUM> , the building 's owners , the port authority of new york and new jersey , issued guidelines to upgrade the fireproofing to a thickness of <NUM> { inches . <SEP> the nist discovered that in <NUM> the port authority issued guidelines to upgrade the fireproofing to a thickness of <NUM> 1 / <NUM> inches
| prd: <GO> in <NUM> , the new 's the , the , , of new new and new <NUM> , , to to to the fireproofing to a of of <NUM> fireproofing <NUM> the <SEP> the nist the that in <NUM> the to to , <NUM> to <NUM> the , to a , of <NUM> to , <NUM> to
| tgt word: ['authority', 'inches', 'that', 'in', 'authority', 'a', '1', '/']
| prd word: [',', '<NUM>', 'that', 'in', 'to', 'a', 'to', ',']
step: 9900 | time: 14.06 | loss: 3.090
| tgt: <MASK> <MASK> stock closed friday at $ <MASK> , down $ <NUM> , or <NUM> percent , on the nasdaq stock market . <MASK> shares of brocade closed at $ <NUM> , down $ <NUM> , or <MASK> percent
| prd: <GO> the <SEP> was friday at $ <NUM> , down $ <NUM> , or <NUM> percent , on the <GO> <SEP> market the <SEP> the of <GO> was at $ <NUM> , down $ <NUM> , or <NUM> percent
| tgt word: ['<GO>', 'the', '<NUM>', '<SEP>', '<NUM>']
| prd word: ['<GO>', 'the', '<NUM>', '<SEP>', '<NUM>']
random_mask_or_replace() 这个功能怎么设计呢?我大概讲一下思路。 简单来说也就是要将原始句子替换一下他们的[MASK]位置,或者是replace成其他词,又或者啥都不做。 我还有个tricky的做法,为了只计算被masked或者replaced这些位置的loss,在模型前向完了,他会对每一个词位都计算一下误差, 但是我们可以在计算真正loss的时候,只保留这些被masked/replaced位置的loss,其他词语的位子都忽略掉。 所以我这里还会生成一个loss_mask,用来在计算loss时,只关注需要计算的部分。
因为BERT的主架构是Transformer的Encoder,而我们之前写的GPT也是用的它的encoder。 还不太清楚我的GPT架构的朋友,请过目一下~ 所以这里我们只需要在GPT的结构上修改一下计算loss的方案和双向mask的方案即可。(我的GPT代码是继承的Transformer的架构,所以他们都是通用的)
所以这个BERT和我的GPT还算挺兼容的,只是稍微改动了下step()和mask().通过这个修改,就保留了BERT的双向注意力,而且在算loss的时候,能只计算需要计算的部分。
最后运行一段时间,注意力的学习成果如下。首先看看它注意力转化成矩阵的模式。

如果将注意力转化成线的模式,我们可以更清楚地看到他对每个词是怎么注意的。这里我们也留意到,其实这个模型还没学好,很多时候,它有点想放弃注意。 也就是很多注意力都集中到<GO>或者一些没多大意义的词上了。随着继续训练和数据的增多,这种现象会好很多。(GPT的训练也类似)
前面我们还提到这个BERT训练了10000步还收敛不到一个好结果,而GPT只需要5000步就能收敛得比较好了。这是为什么呢? 最主要的原因是BERT每次的训练太没有效率了。每次输入全部训练数据,但是只能预测15%的词,而GPT能够预测100%的词,这不就让BERT单次训练少了很多有效的label信息。
为了解决我刚刚提到的训练无效率的问题,我自己也捣腾了一下修改BERT的结构,让它能快速训练。下面就是我自己的原创模型啦。
提升训练速度(待讨论)¶
BERT 的训练真的很慢!!Google都要用很厉害的8块GPU训练一周时间才能训练一个好的模型。 这只有他们这种土豪才能玩的模型,到我们手中,谁等得起。 因为BERT每次训练只预测并训练约15%的信息量,这种训练是十分低效的。 如果你对比前面的GPT教学,就会发现GPT的训练比Bert快多了。 所以我也在考虑如何结合GPT的优点,将BERT的训练速度加快。
总的来说,BERT因为需要mask并预测mask的信息,使得模型在预测时的数据处理就要多一个随机环境。最慢的还不是这个随机过程,而是mask训练的方案。 如果从预测并训练15%的token提升到100%,速度一下就提高了6倍多,原本要8块GPU一周,变成8块一天,岂不是更好~
所以我也想出了一种训练方案,我没有仔细在论文中寻找是否已经存在这种方案了,如果你看过这样的方案,欢迎在留言区留言,我cite一下。如果没有,那么请恭喜我, 莫烦Python可能是这个世界上第一次(2020年7月)提出这种快速训练BERT方案的人。 也欢迎各路学术上的朋友参考一下,发发论文啥的。
不过这个方案目前还是不太完善,也需要你的讨论和补充,因为它能避免第一层self-attention的信息穿越,但是到了第二层self-attention, attention 和 v 的矩阵点乘时,信息还是会有一定程度的穿越,我在后续会提到这个问题。

GPT中, 我们保留前句,mask掉后句,然后用前句预测后句中的第一个词。但是在GPT预测后句中第一个词时, 是没有考虑后句中其他的信息,所以我们也称为GPT是单向Transformer。像BERT这种模型,因为在预测时考虑了除mask外的所有前后文,所以也被叫做双向Transformer。 如果要保留BERT的双向性,又要让BERT不仅仅只预测15%的信息,那么好办, 我只要让BERT在attention的时候mask掉对角线的token(词),而不是mask输入端(word Embedding前)的15%个token。

这样看似BERT在预测某个token(词)的时候,就看不见这个token的attention了,完美~ 不对!!这其实还是有个问题的。除了attention层, 我们还有一个残差层。
我们原以为attention时看不见就行了,但是这个残差中的映射部分成会将原本看不见的X信息直接传到后面的层去,所以最后预测 attention 的 mask 位置X时, 其实早就通过残差中的映射看过masked token的信息了,这是一种有透视的
无效预测。
那么怎么解决这个透视
问题呢?咱们学学GPT,在预测的时候,不要在X位置上预测X的信息,而是预测X位置上的X+1信息。同时为了保证BERT语言模型的双向性, 我们只在X的attention位置上 mask 掉 X+1 信息,然后用X位置快速训练BERT方案预测X+1。即使映射会将X的信息传递到后面去,但是X+1的信息它还是没见过的。 我称为BERT的next-mask机制。

具体代码也在我的github中, 和我写的BERT代码非常像,但是更加简单了, 没了哪些随机采样对训练数据采样的操作。
另外,基于这个想法再括展一些,还可以引入w2v CBOW的训练概念。 改一改attention mask,在X的token位置预测(X-n)~(X+n)范围的token。这样就比GPT更强,而且还保留了双向的特性。一举两得。

通过这种方法训练,我们可以更快训练好一个bert。


不过通过这种途径,第一层self-attention可以避免掉X信息传递到X+1的预测位上,但是如果你看到这个评论区的2020年10月29号与意外之外
的讨论, 会发现在第二层和后续层还是有一些穿越的问题。在下面,我简单说明一下信息是如何穿越的。
注:下面的 @ 表示矩阵点乘,()表示矩阵中某个item的信息是从哪些位置来的,[]表示()所有信息来源位置汇总。
假设一个GPT有两层self-attention layer, 我们看看GPT信息是如何传递的:
# layer 1
# q@k = attention + mask 以后的结果, 维度[step, step]:
100
110
111
# v 维度[step, dim]:
0
1
2
# attention@v 维度[step, dim]:
100 0 = (0) # 有t0的信息
110 @ 1 = (01) # 有t0,t1的信息
111 2 = (012) # 有t0,t1,t2的信息
# layer2: attention@v
100 (0) = (0) ~ [0] # 有t0
110 @ (01) = (0)(01) ~ [01] # 有t0,t1的信息
111 (012) = (0)(01)(012)~[012] # 有t0,t1,t2的信息
那么原来bert的方式呢?下面attention虽然全开了,但是也不造成-, 1号位置的信息穿越,因为v中不会有1号位的信息。
# layer 1
# q@k = attention + mask 以后的结果, 维度[step, step]:
111
111
111
# v, 假设遮住了第1位,维度[step, dim]:
0
-
2
# attention@v 维度[step, dim]:
111 0-2 = (02) # 有t0,t2的信息
111 @ 0-2 = (02) # 有t0,t2的信息
111 0-2 = (02) # 有t0,t2的信息
# layer2: attention@v
111 (02) = (02)(02)(02) ~ [02] # 有t0,t2的信息
111 @ (02) = (02)(02)(02) ~ [02] # 有t0,t2的信息
111 (02) = (02)(02)(02) ~ [02] # 有t0,t2的信息
但是在我提到的bert加速版中,穿越还是到来了。虽然这是一种隐秘的穿越
。
# layer 1
# q@k = attention + mask 以后的结果, 维度[step, step]:
101
110
111
# v,维度[step, dim]:
0
1
2
# attention@v 维度[step, dim]:
101 012 = (02) # 有t0,t2的信息
110 @ 012 = (01) # 有t0,t1的信息
111 012 = (012) # 有t0,t1,t2的信息
# layer2: attention@v
101 (02) = (02)(012) ~ [012] # 有t0,t1,t2的信息
110 @ (01) = (02)(01) ~ [012] # 有t0,t1,t2的信息
111 (012) = (02)(01)(012) ~ [012] # 有t0,t1,t2的信息
你看,虽然在第一层没有信息穿越,但是到了第二层中,之前的v中带有混杂在一起的012位的信息,虽然attention那边并没有问题, 但是信息会从v中传递到后面的层。感谢意外之外
与我在讨论区中的讨论, 发现了这一个潜在的问题。 但是还有几个问题,这种重组信息带来的信息穿越会有多大影响?会不会在任务上带来负面影响?在获得速度的基础上是不是会牺牲掉一些精确度? 对比AutoEncoder的X预测X的方式是,它同样会遇到信息穿越的问题,但是它通过压缩
和解压
的方式,在信息穿越中加入了信息重组的概念。 是否也可以引入这些概念来优化我这种bert训练加速方案呢?
我在网上找到的类似加速想法还有 Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning.
我就不发论文了,想拿着这个想法发论文的朋友欢迎email和我联系(mofanpy@hotmail.com)。
总结¶
BERT 完美实现了双向语言模型的概念,在我的认知中,双向肯定会比单向语言模型(GPT)获取到更多的信息,所以按理来说应该会更优秀。但是在训练双向语言模型时, 会有很多tricks,我们要多多研究一下trick才能使得训练更加有效率更快。
