

Asynchronous Advantage Actor-Critic (A3C)
学习资料:
- 强化学习教程
- 强化学习模拟程序
- A3C Tensorflow 教程
- A3C Pytorch 代码
- 强化学习实战
- 论文 Asynchronous Methods for Deep Reinforcement Learning
今天我们会来说说强化学习中的一种有效利用计算资源, 并且能提升训练效用的算法, Asynchronous Advantage Actor-Critic, 简称 A3C.
注: 本文不会涉及数学推导. 大家可以在很多其他地方找到优秀的数学推导文章.
平行宇宙¶

我们先说说没什么关系的,大家知道平行宇宙这回事. 想像现在有三个平行宇宙, 那么就意味着这3个平行宇宙上存在3个你, 而你可能在电脑前呆了很久, 对, 说的就是你! 然后你会被我催促起来做运动~ 接着你 和 你 还有 你, 就无奈地在做着不同的运动, 油~ 我才不想知道你在做什么样的运动呢. 不过这3个你 都开始活动胫骨啦. 假设3个你都能互相通信, 告诉对方, “我这个动作可以有效缓解我的颈椎病”, “我做那个动作后, 腰就不痛了 “, “我活动了手臂, 肩膀就不痛了”. 这样你是不是就同时学到了对身体好的三招. 这样是不是感觉特别有效率. 让你看看更有效率的, 那就想想3个你同时在写作业, 一共3题, 每人做一题, 只用了1/3 的时间就把作业做完了. 感觉棒棒的. 哈, 你看出来了, 如果把这种方法用到强化学习, 岂不是 “牛逼lity”.
平行训练¶

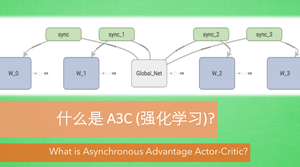
这就是传说中的 A3C. A3C 其实只是这种平行方式的一种而已, 它采用的是我们之前提到的 Actor-Critic 的形式. 为了训练一对 Actor 和 Critic, 我们将它复制多份红色的, 然后同时放在不同的平行宇宙当中, 让他们各自玩各的. 然后每个红色副本都悄悄告诉黑色的 Actor-Critic 自己在那边的世界玩得怎么样, 有哪些经验值得分享. 然后还能从黑色的 Actor-Critic 这边再次获取综合考量所有副本经验后的通关秘籍. 这样一来一回, 形成了一种有效率的强化学习方式.
多核训练¶

我们知道目前的计算机多半是有双核, 4核, 甚至 6核, 8核. 一般的学习方法, 我们只能让机器人在一个核上面玩耍. 但是如果使用 A3C 的方法, 我们可以给他们安排去不同的核, 并行运算. 实验结果就是, 这样的计算方式往往比传统的方式快上好多倍. 那我们也多用用这样的红利吧.
